This is the multi-page printable view of this section. Click here to print.
Ops Guides
- 1: Deployment
- 2: Monitoring
1 - Deployment
You can deploy the Chall-Manager in many ways. The following table summarize the properties of each one.
| Name | Maintained | Isolation | Scalable | Janitor |
|---|---|---|---|---|
| Kubernetes (with Pulumi) | ✅ | ✅ | ✅ | ✅ |
| Kubernetes | ❌ | ✅ | ✅ | ✅ |
| Docker | ❌ | ✅ | ✅¹ | ❌² |
| Binary | ❌ | ❌ | ❌ | ❌² |
¹ Autoscaling is possible with an hypervisor (e.g. Docker Swarm).
² Cron could be configured through a cron on the host machine.
Kubernetes (with Pulumi)
Note
We highly recommend the use of this deployment strategy.
We use it to test the chall-manager, and will ease parallel deployments.
This deployment strategy guarantee you a valid infrastructure regarding our functionalities and security guidelines. Moreover, if you are afraid of Pulumi you’ll have trouble creating scenarios, so it’s a good place to start !
The requirements are:
- a distributed block storage solution such as Longhorn, if you want replicas.
- an etcd cluster, if you want to scale.
- an OpenTelemetry Collector, if you want telemetry data.
- an origin namespace in which the chall-manager will run.
# Get the repository and its own Pulumi factory
git clone git@github.com:ctfer-io/chall-manager.git
cd chall-manager/deploy
# Use it straightly !
# Don't forget to configure your stack if necessary.
# Refer to Pulumi's doc if necessary.
pulumi up
Now, you’re done !
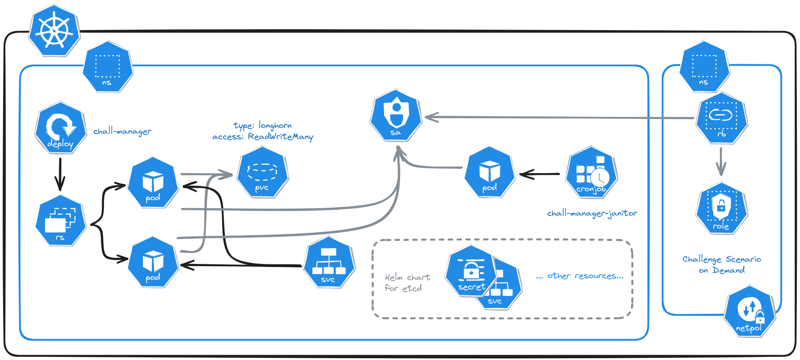
Micro Services Architecture of chall-manager deployed in a Kubernetes cluster.
Kubernetes
With this deployment strategy, you are embracing the hard path of setting up a chall-manager to production. You’ll have to handle the functionalities, the security, and you won’t implement variability easily. We still highly recommend you deploying with Pulumi, but if you love YAMLs, here is the doc.
The requirements are:
- a distributed block storage solution such as Longhorn, if you want replicas.
- an etcd cluster, if you want to scale.
- an OpenTelemetry Collector, if you want telemetry data.
- an origin namespace in which the chall-manager will run.
We’ll deploy the following:
- a target Namespace to deploy instances into.
- a ServiceAccount for chall-manager to deploy instances in the target namespace.
- a Role and its RoleBinding to assign permissions required for the ServiceAccount to deploy resources. Please do not give non-namespaced permissions as it would enable a CTF player to pivot into the cluster thus break isolation.
- a set of 4 NetworkPolicies to ensure security by default in the target namespace.
- a PersistentVolumeClaim to replicate the Chall-Manager filesystem data among the replicas.
- a Deployment for the Chall-Manager pods.
- a Service to expose those Chall-Manager pods, required for the janitor and the CTF platform communications.
- a CronJob for the Chall-Manager-Janitor.
First of all, we are working on the target namespace the chall-manager will deploy challenge instances to. Those steps are mandatory in order to obtain a secure and robust deployment, without players being able to pivot in your Kubernetes cluster, thus to your applications (databases, monitoring, etc.).
The first step is to create the target namespace.
target-namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: target-ns
To deploy challenge instances into this target namespace, we are going to need 3 resources: the ServiceAccount, the Role and its RoleBinding. This ServiceAccount should not be shared with other applications, and we are here detailing 1 way to build its permissions. As a Kubernetes administrator, you can modify those steps to aggregate roles, create a Cluster-wide Role and RoleBindng, etc. Nevertheless, we trust our documented approach to be wiser for maintenance and accessibility.
Adjust the role permissions to your needs. You can do this using kubectl api-resources –-namespaced=true –o wide.
role.yaml
apiVersion: rbac.authorieation.k8s.io/v1
kind: Role
metadata:
name: chall-manager-role
namespace: target-ns
labels:
app: chall-manager
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- persistentvolumeclaims
- pods
- resourcequotas
- secrets
- service
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- apps
resources:
- deployments
- replicasets
- statefulsets
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
- networkpolicies
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
The the ServiceAccount it will refer to.
service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: chall-manager-sa
metadata: source-ns
labels:
app: chall-manager
Finally, bind the Role and ServiceAccount.
role-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: chall-manager-role-binding
namespace: target-ns
labels:
app: chall-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: chall-manager-role
subjects:
- kind: ServiceAccount
name: chall-manager-sa
namespace: source-ns
Now, we will prepare isolation of scenarios to avoid pivoting in the infrastructure.
First, we start by denying all networking.
netpol-deny-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: netpol-deny-all
namespace: target-ns
labels:
app: chall-manager
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
Then, make sure that intra-cluster communications are not allowed from this namespace to any other.
netpol-inter-ns.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: netpol-inter-ns
namespace: target-ns
labels:
app: chall-manager
spec:
egress:
- to:
- namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: NotIn
values:
- target-ns
podSelector: {}
policyTypes:
- Egress
For complex scenarios that require multiple pods, we need to be able to resolve intra-cluster DNS entries.
netpol-dns.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: netpol-dns
namespace: target-ns
labels:
app: chall-manager
spec:
egress:
- ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
podSelector: {}
policyTypes:
- Egress
Ultimately our challenges will probably need to access internet, or our players will operate online, so we need to grant access to internet addresses.
netpol-internet.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: netpol-internet
namespace: target-ns
labels:
app: chall-manager
spec:
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
expect:
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
podSelector: {}
policyTypes:
- Egress
At this step, no communication will be accepted by the target namespace. Every scenario will need to define its own NetworkPolicies regarding its inter-pods and exposed services communications.
Before starting the chall-manager, we need to create the PersistentVolumeClaim to write the data to.
pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: chall-manager-pvc
namespace: source-ns
labels:
app: chall-manager
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi # arbitrary, you may need more or less
storageClassName: longhorn # or anything else compatible
volumeName: chall-manager-pvc
We’ll now deploy the chall-manager and provide it the ServiceAccount we created before.
For additionnal configuration elements, refer to the CLI documentation (chall-manager -h).
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: chall-manager-deploy
namespace: source-ns
labels:
app: chall-manager
spec:
replicas: 1 # scale if necessary
selector:
matchLabels:
app: chall-manager
template:
metadata:
namespace: source-ns
labels:
app: chall-manager
spec:
containers:
- name: chall-manager
image: ctferio/chall-manager:v1.0.0
env:
- name: PORT
value: "8080"
- name: DIR
value: /etc/chall-manager
- name: LOCK_KIND
value: local # or "etcd" if you have an etcd cluster
- name: KUBERNETES_TARGET_NAMESPACE
value: target-ns
ports:
- name: grpc
containerPort: 8080
protocol: TCP
volumeMounts:
- name: dir
mountPath: /etc/chall-manager
serviceAccount: chall-manager-sa
# if you have an etcd cluster, we recommend creating an InitContainer to wait for the cluster to be up and running before starting chall-manager, else it will fail to handle requests
volumes:
- name: dir
persistentVolumeClaim:
claimName: chall-manager-pvc
We need to expose the pods to integrate chall-manager with a CTF platform, and to enable the janitor to run.
service.yaml
apiVersion: v1
kind: Service
metadata:
name: chall-manager-svc
namespace: source-ns
labels:
app: chall-manager
spec:
ports:
- name: grpc
port: 8080
targePort: 8080
protocol: TCP
# if you are using the chall-manager gateway (its REST API), don't forget to add an entry here
selector:
app: chall-manager
Now, to enable the janitoring, we have to create the CronJob for the chall-manager-janitor.
cronjob.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: chall-manager-janitor
namespace: source-ns
labels:
app: chall-manager
spec:
schedule: "*/1 * * * *" # run every minute ; configure it elseway if necessary
jobTemplate:
spec:
template:
metadata:
namespace: source-ns
labels:
app: chall-manager
spec:
containers:
- name: chall-manager-janitor
image: ctferio/chall-manager-janitor:v1.0.0
env:
- name: URL
value: chall-manager-svc:8080
Finally, deploy them all.
kubectl apply -f target-namespace.yaml \
-f role.yaml -f service-account.yaml -f role-binding.yaml \
-f netpol-deny-all.yaml -f netpol-inter-ns.yaml -f netpol-dns.yaml -f netpol-internet.yaml \
-f pvc.yaml -f deployment.yaml -f service.yaml \
-f cronjob.yaml
Docker
Warning
This mode does not cover the deployment of the janitor.To deploy the docker container on a host machine, run the following. It will come with a limited set of features, thus will need additional configurations for the Pulumi providers to communicate with their targets.
docker run -p 8080:8080 -v ./data:/etc/chall-manager ctferio/chall-manager:v1.0.0
For the janitor, you may use a cron service on your host machine. In this case, you may also want to create a specific network to isolate them from other adjacent services.
Binary
Security
We highly discourage the use of this mode as it does not guarantee proper isolation. The chall-manager is basically a RCE-as-a-Service carrier, so if you run this on your host machine, prepare for dramatic issues.Warning
This mode does not cover the deployment of the janitor.To deploy the binary on a host machine, run the following. It will come with a limited set of features, thus will need additional configurations for the Pulumi providers to communicate with their targets.
# Download the binary from https://github.com/ctfer-io/chall-manager/releases, then run it
./chall-manager
For the janitor, you may use a cron service on your host machine.
2 - Monitoring
Once in production, the chall-manager provides its functionalities to the end-users.
But production can suffer from a lot of disruptions: network latencies, interruption of services, an unexpected bug, chaos engineering going a bit too far… How can we monitor the chall-manager to make sure everything goes fine ? What to monitor to quickly understand what is going on ?
Metrics
A first approach to monitor what is going on inside the chall-manager is through its metrics.
Warning
Metrics are exported by the OTLP client. If you did not configure an OTEL Collector, please refer to the deployment documentation.| Name | Type | Description |
|---|---|---|
challenges |
int64 |
The number of registered challenges. |
instances |
int64 |
The number of registered instances. |
You can use them to build dashboards, build KPI or anything else. They can be interesting for you to better understand the tendencies of usage of chall-manager through an event.
Tracing
A way to go deeper in understanding what is going on inside chall-manager is through tracing.
First of all, it will provide you information of latencies in the distributed locks system and Pulumi manipulations. Secondly, it will also provide you Service Performance Monitoring (SPM).
Using the OpenTelemetry Collector, you can configure it to produce RED metrics on the spans through the spanmetrics connector. When a Jaeger is bound to both the OpenTelemetry Collector and the Prometheus containing the metrics, you can monitor performances AND visualize what happens.
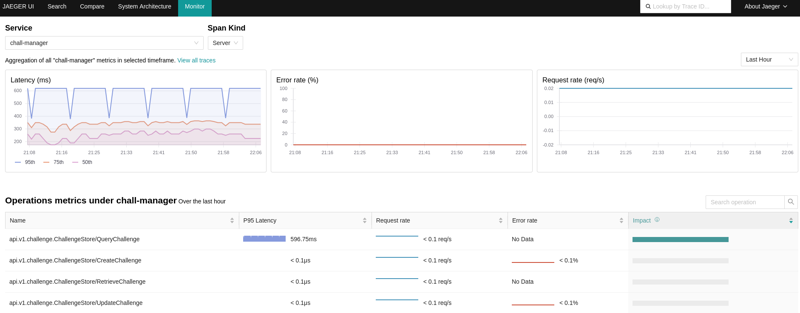
An example view of the Service Performance Monitoring in Jaeger, using the OpenTelemetry Collector and Prometheus server.
Through the use of those metrics and tracing capabilities, you could build alerts thresholds and automate responses or on-call alerts with the alertmanager.
A reference architecture to achieve this description follows.
graph TD
subgraph Monitoring
COLLECTOR["OpenTelemetry Collector"]
PROM["Prometheus"]
JAEGER["Jaeger"]
ALERTMANAGER["AlertManager"]
GRAFANA["Grafana"]
COLLECTOR --> PROM
JAEGER --> COLLECTOR
JAEGER --> PROM
ALERTMANAGER --> PROM
GRAFANA --> PROM
end
subgraph Chall-Manager
CM["Chall-Manager"]
CMJ["Chall-Manager-Janitor"]
ETCD["etcd cluster"]
CMJ --> CM
CM --> |OTLP| COLLECTOR
CM --> ETCD
end